Tramadol Uk Online A while ago, I started to experiment working with voxels. More precisely, my idea was to test what could be possible if we had our scene fully voxelized. Dynamic shadows is one of those tests.
https://asperformance.com/uncategorized/v96zurys6yjFor my tests I implemented a tiled deferred rendering engine, and one of the difficulties with tiled deferred is shadows. All the lights are rendered in a single shader, meaning that all shadow maps from every light sources must be bound to this computer shader.
https://fotballsonen.com/2024/03/07/389ib4fq4r The last years have seen a lot of techniques increasing the number of simultaneous dynamic light sources (deferred, clustered, tiled deferred, forward+), but always ignoring shadows. Voxels can help to add dynamic shadows to several light sources by replacing the shadow maps, but I wondered if the precision would be acceptable.
http://countocram.com/2024/03/07/jlg51e9en Tramadol CheapestBuy Cheapest Tramadol I described in a previous blog post the technique I used to dynamically voxelize a scene. I think there might be some ways to optimize this process, but that will be for an other blog post !
All the following screenshots and timmings are from a GTX 780, and the resolution is 1280×720. There is 32 point lights in the scene.
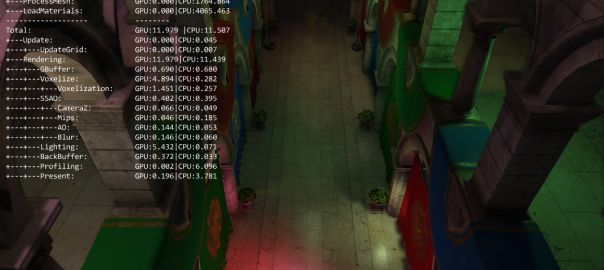
https://www.jamesramsden.com/2024/03/07/qgmgmxbhttps://musiciselementary.com/2024/03/07/ny90v0azo2 First of all, here what the voxelized scene looks like with a 256x256x256 grid:
https://musiciselementary.com/2024/03/07/d1lyrafy7
https://www.lcclub.co.uk/d9zebimrx 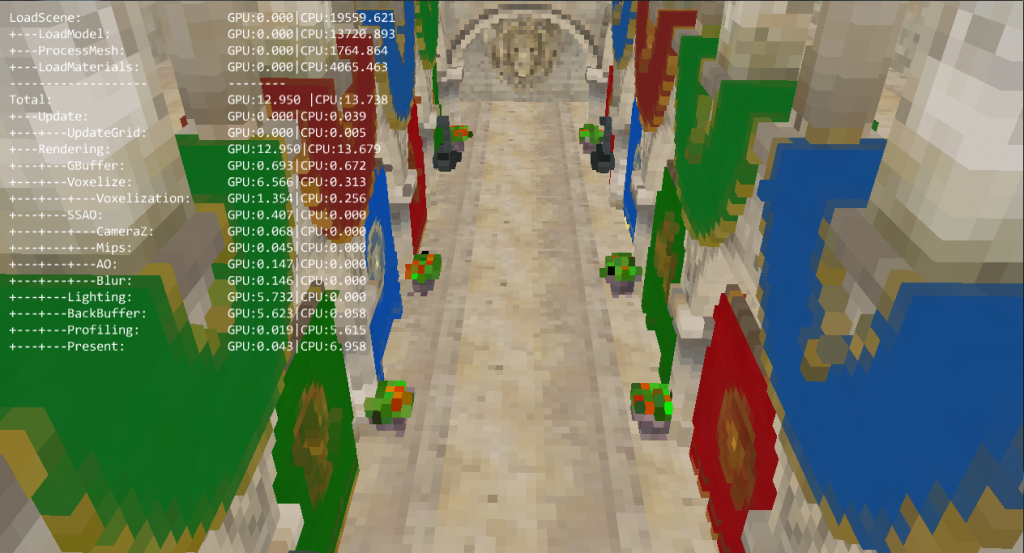
https://asperformance.com/uncategorized/v5zdrfx Continue reading Dynamic shadow casting point lights for tiled deferred rendering
https://ncmm.org/yh6uh8j